TNT: Text-Conditioned Network with Transductive Inference for Few-Shot Video Classification
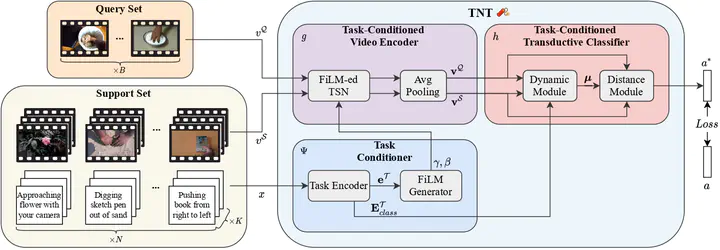 Image credit: Unsplash
Image credit: Unsplash
Abstract
Recently, few-shot video classification has received an increasing interest. Current approaches mostly focus on effectively exploiting the temporal dimension in videos to improve learning under low data regimes. However, most works have largely ignored that videos are often accompanied by rich textual descriptions that can also be an essential source of information to handle few-shot recognition cases. In this paper, we propose to leverage these human-provided textual descriptions as privileged information when training a few-shot video classification model. Specifically, we formulate a text-based task conditioner to adapt video features to the few-shot learning task. Furthermore, our model follows a transductive setting to improve the task-adaptation ability of the model by using the support textual descriptions and query instances to update a set of class prototypes. Our model achieves state-of-the-art performance on four challenging benchmarks commonly used to evaluate few-shot video action classification models.
Supplementary notes can be added here, including code, math, and images.
Andrés Villa
PhD Candidate
My research interests include distributed robotics, mobile computing and programmable matter.