Biography
I have always stood out for my responsibility, perseverance, excellent academic results, and good technical and research skills. In this way, I have achieved several academic recognitions, among which Erasmus Mundus scholarship and ANID scholarship awarded by the Chilean government to do a PhD in computer science. Currently, I am PhD Candidate at IALab group PUC, passionate about computer vision. I’m trying to figure out how to give the machines and artificial agents the ability to reason and see the world as human beings do. Inspired by this, I am focusing on learning to recognize novel human actions with few samples and multimodal information like humans do.
Download my resumé.
- Video Understanding
- Few-Shot Learning
- Continual Learning
- Class Incremental Learning
- Human Action Classification
-
PhD in Computer Science, (March 2019 - Present)
Pontificia Universidad Católica de Chile
-
Bs. Electronic Engineering, (February 2012 - March 2017)
Universidad del Norte, Barranquilla
-
Academic Exchange, (September 2015 - July 2016)
Universidad Politécnica de Madrid
Experience
Main topics:
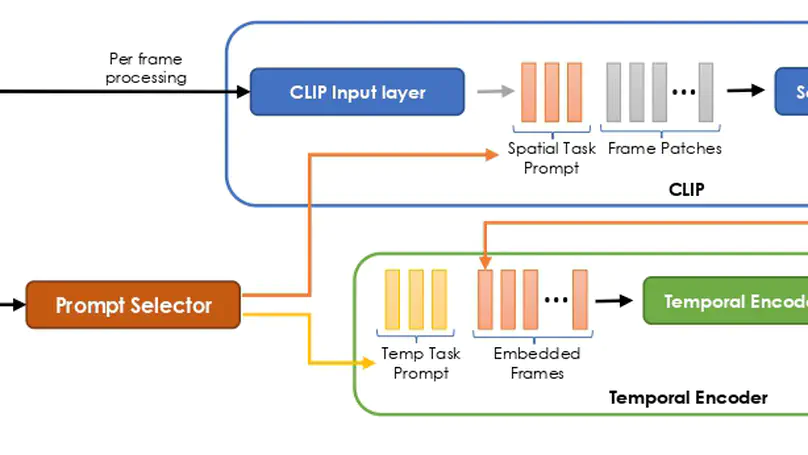
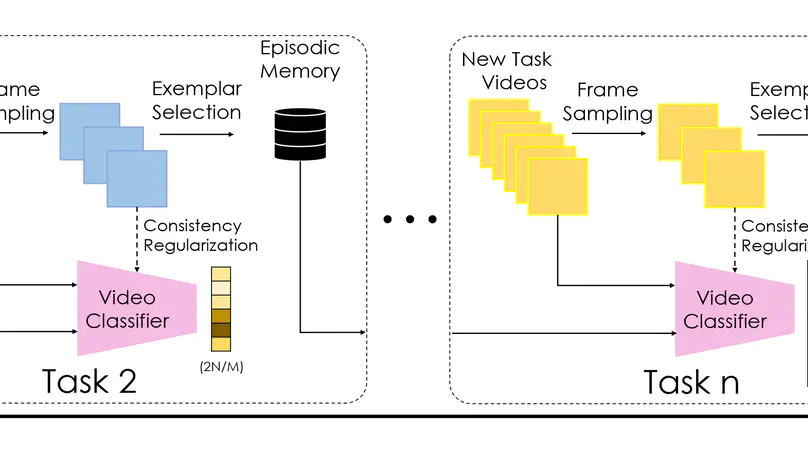
- Class incremental learning for action classification
- Continual learning
Main topics:
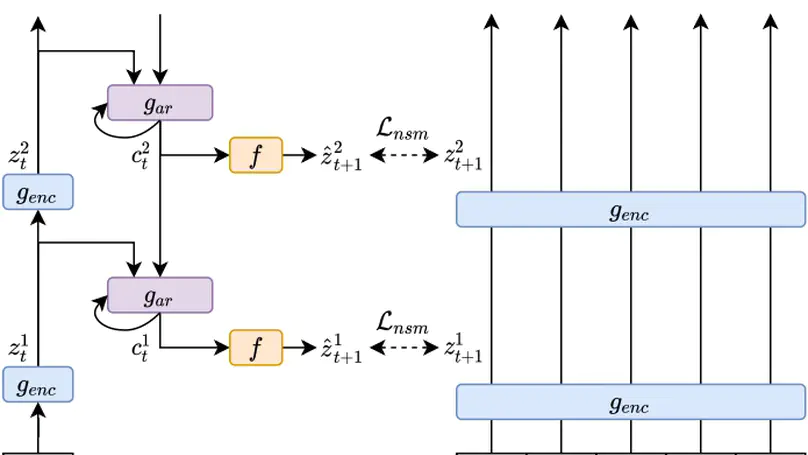
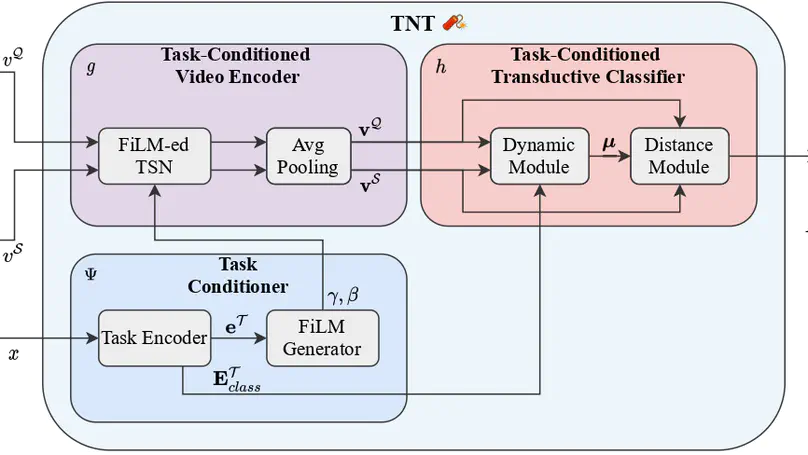
- Few-Shot learning for video understanding
- Multimodal models
- Human action recognition
- Attention
- Transductive inference
Functions:
- Teach the principal motivations behind the tasks of Video Understanding and Visual question answering and how these tasks have been addressed
- Explain inductive artificial intelligence techniques such as SVM, Random Forest, Naive Bayes, Neural Networks, Deep Learning, etc
- Prepare exercises for the students
- Solve doubts about the laboratories and grade these
- Courses: Artificial Intelligence, Introduction to programming, Deep Learning, Recommender Systems, Visual Question Answering, Video understanding
Functions:
- Develop new features for cross-platform applications which are designed for vaccine management using frameworks like Ionic
- Develop new web applications and maintain existing ones, both frontend, and backend parts
- Deploy the mobile solutions in the Play Store for Android devices and the App Store for iOS devices